A More Complex Example
Imagine a Bayesian Gaussian mixture model described as follows:

Note:
- SymDir is the symmetric Dirichlet distribution of dimension, with the hyperparameter for each component set to . The Dirichlet distribution is the conjugate prior of the categorical distribution or multinomial distribution.
- is the Wishart distribution, which is the conjugate prior of the precision matrix (inverse covariance matrix) for a multivariate Gaussian distribution.
- Mult is a multinomial distribution over a single observation (equivalent to a categorical distribution). The state space is a "one-of-K" representation, i.e. a -dimensional vector in which one of the elements is 1 (specifying the identity of the observation) and all other elements are 0.
- is the Gaussian distribution, in this case specifically the multivariate Gaussian distribution.
The interpretation of the above variables is as follows:
- is the set of data points, each of which is a -dimensional vector distributed according to a multivariate Gaussian distribution.
- is a set of latent variables, one per data point, specifying which mixture component the corresponding data point belongs to, using a "one-of-K" vector representation with components for, as described above.
- is the mixing proportions for the mixture components.
- and specify the parameters (mean and precision) associated with each mixture component.
The joint probability of all variables can be rewritten as
where the individual factors are

where
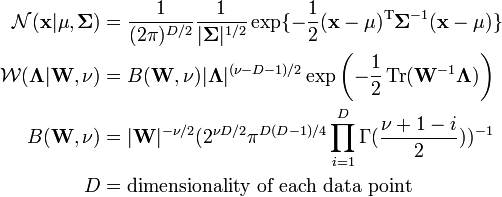
Assume that .
Then

where we have defined
Exponentiating both sides of the formula for yields
Requiring that this be normalized ends up requiring that the sum to 1 over all values of, yielding
where
In other words, is a product of single-observation multinomial distributions, and factors over each individual, which is distributed as a single-observation multinomial distribution with parameters for .
Furthermore, we note that
which is a standard result for categorical distributions.
Now, considering the factor, note that it automatically factors into due to the structure of the graphical model defining our Gaussian mixture model, which is specified above.
Then,

Taking the exponential of both sides, we recognize as a Dirichlet distribution
where
where
Finally
Grouping and reading off terms involving and, the result is a Gaussian-Wishart distribution given by
given the definitions

Finally, notice that these functions require the values of, which make use of, which is defined in turn based on, and . Now that we have determined the distributions over which these expectations are taken, we can derive formulas for them:

These results lead to
These can be converted from proportional to absolute values by normalizing over so that the corresponding values sum to 1.
Note that:
- The update equations for the parameters, and of the variables and depend on the statistics, and, and these statistics in turn depend on .
- The update equations for the parameters of the variable depend on the statistic, which depends in turn on .
- The update equation for has a direct circular dependence on, and as well as an indirect circular dependence on, and through and .
This suggests an iterative procedure that alternates between two steps:
- An E-step that computes the value of using the current values of all the other parameters.
- An M-step that uses the new value of to compute new values of all the other parameters.
Note that these steps correspond closely with the standard EM algorithm to derive a maximum likelihood or maximum a posteriori (MAP) solution for the parameters of a Gaussian mixture model. The responsibilities in the E step correspond closely to the posterior probabilities of the latent variables given the data, i.e. ; the computation of the statistics, and corresponds closely to the computation of corresponding "soft-count" statistics over the data; and the use of those statistics to compute new values of the parameters corresponds closely to the use of soft counts to compute new parameter values in normal EM over a Gaussian mixture model.
Read more about this topic: Variational Bayesian Methods
Famous quotes containing the word complex:
“Uneducated people are unfortunate in that they do grasp complex issues, educated people, on the other hand, often do not understand simplicity, which is a far greater misfortune.”
—Franz Grillparzer (1791–1872)