Four Parameters
If are independent random variables each having a beta distribution with four parameters: the exponents α and β, as well as "a" (the minimum of the distribution range), and "c" (the maximum of the distribution range) (section titled "Alternative parametrizations", "Four parameters"), with probability density function:
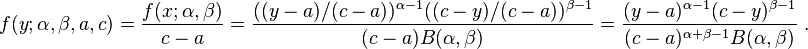
the joint log likelihood function per N iid observations is:
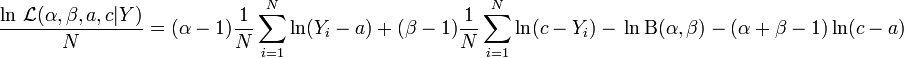
For the four parameter case, the Fisher information has 4*4=16 components. It has 12 off-diagonal components = (4*4 total - 4 diagonal). Since the Fisher information matrix is symmetric, half of these components (12/2=6) are independent. Therefore the Fisher information matrix has 6 independent off-diagonal + 4 diagonal = 10 independent components. Aryal and Nadarajah calculated Fisher's information matrix for the four parameter case as follows:
In the above expressions, the use of X instead of Y in the expressions is not an error. The expressions in terms of the log geometric variances and log geometric covariance occur as functions of the two parameter parametrization because when taking the partial derivatives with respect to the exponents (α, β) in the four parameter case, one obtains the identical expressions as for the two parameter case: these terms of the four parameter Fisher information matrix are independent of the minimum "a" and maximum "c" of the distribution's range. The only non-zero term upon double differentiation of the log likelihood function with respect to the exponents α and β is the second derivative of the log of the beta function: . This term is independent of the minimum "a" and maximum "c" of the distribution's range. Double differentiation of this term results in trigamma functions. The sections titled "Maximum likelihood", "Two unknown parameters" and "Four unknown parameters" also show this fact.
The Fisher information for N i.i.d. samples is N times the individual Fisher information (eq. 11.279, page 394 of Cover and Thomas). (Aryal and Nadarajah take a single observation, N=1, to calculate the following components of the Fisher information, which leads to the same result as considering the derivatives of the log likelihood per N observations):
(In the above expression the erroneous expression for in Aryal and Nadarajah has been corrected.)
The lower two diagonal entries of the Fisher information matrix, with respect to the parameter "a" (the minimum of the distribution's range):, and with respect to the parameter "c" (the maximum of the distribution's range): are only defined for exponents α > 2 and β > 2 respectively. The Fisher information matrix component for the minimum "a" approaches infinity for exponent α approaching 2 from above, and the Fisher information matrix component for the maximum "c" approaches infinity for exponent β approaching 2 from above.
The Fisher information matrix for the four parameter case does not depend on the individual values of the minimum "a" and the maximum "c", but only on the total range (c - a). Moreover, the components of the Fisher information matrix that depend on the range (c - a), depend only through its inverse (or the square of the inverse), such that the Fisher information decreases for increasing range (c - a).
The accompanying images show the Fisher information components and . Images for the Fisher information components and are shown in the section titled "Geometric variance". All these Fisher information components look like a basin, with the "walls" of the basin being located at low values of the parameters.
The following four-parameter-beta-distribution Fisher information components can be expressed in terms of the two-parameter : expectations of the transformed ratio ((1-X)/X) and of its mirror image (X/(1-X)), scaled by the range (c-a), which may be helpful for interpretation:
These are also the expected values of the "inverted beta distribution" or beta prime distribution (also known as beta distribution of the second kind or Pearson's Type VI) and its mirror image, scaled by the range (c-a).
Also, the following Fisher information components can be expressed in terms of the harmonic (1/X) variances or of variances based on the ratio transformed variables ((1-X)/X) as follows:
See section "Moments of linearly-transformed, product and inverted random variables" for these expectations.
The determinant of Fisher's information matrix is of interest (for example for the calculation of Jeffreys prior probability). From the expressions for the individual components, it follows that the determinant of Fisher's (symmetric) information matrix for the beta distribution with four parameters is:

Using Sylvester's criterion (checking whether the diagonal elements are all positive), and since diagonal components and have singularities at α=2 and β=2 it follows that the Fisher information matrix for the four parameter case is positive-definite for α>2 and β>2. Since for α>2 and β>2 the beta distribution is (symmetric or unsymmetric) bell shaped, it follows that the Fisher information matrix is positive-definite only for bell-shaped (symmetric or unsymmetric) beta distributions, with inflection points located to either side of the mode. Thus, important well known distributions belonging to the four-parameter beta distribution family, like the parabolic distribution (Beta(2,2,a,c)) and the uniform distribution (Beta(1,1,a,c)) have Fisher information components that blow up (approach infinity) in the four-parameter case (although their Fisher information components are all defined for the two parameter case). The four-parameter Wigner semicircle distribution (Beta(3/2,3/2,a,c)) and arcsine distribution (Beta(1/2,1/2,a,c)) have negative Fisher information determinants for the four-parameter case.
Read more about this topic: Beta Distribution, Parameter Estimation, Fisher Information Matrix
Famous quotes containing the word parameters:
“What our children have to fear is not the cars on the highways of tomorrow but our own pleasure in calculating the most elegant parameters of their deaths.”
—J.G. (James Graham)
“Men have defined the parameters of every subject. All feminist arguments, however radical in intent or consequence, are with or against assertions or premises implicit in the male system, which is made credible or authentic by the power of men to name.”
—Andrea Dworkin (b. 1946)