Fisher Information Matrix
Let a random variable X have a probability density f(x;α). The partial derivative with respect to the (unknown, and to be estimated) parameter α of the log likelihood function is called the score. The second moment of the score is called the Fisher information:

The expectation of the score is zero, therefore the Fisher information is also the second moment centered around the mean of the score: the variance of the score.
If the log likelihood function is twice differentiable with respect to the parameter α, and under certain regularity conditions, then the Fisher information may also be written as follows (which is often a more convenient form for calculation purposes):
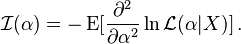
Thus, the Fisher information is the negative of the expectation of the second derivative with respect to the parameter α of the log likelihood function. Therefore Fisher information is a measure of the curvature of the log likelihood function of α. A low curvature (and therefore high radius of curvature), flatter log likelihood function curve has low Fisher information; while a log likelihood function curve with large curvature (and therefore low radius of curvature) has high Fisher information. When the Fisher information matrix is computed at the evaluates of the parameters ("the observed Fisher information matrix") it is equivalent to the replacement of the true log likelihood surface by a Taylor's series approximation, taken as far as the quadratic terms. The word information, in the context of Fisher information, refers to information about the parameters. Information such as: estimation, sufficiency and properties of variances of estimators. The Cramér–Rao bound states that the inverse of the Fisher information is a lower bound on the variance of any estimator of a parameter α:

The precision to which one can estimate the estimator of a parameter α is limited by the Fisher Information of the log likelihood function. The Fisher information is a measure of the minimum error involved in estimating a parameter of a distribution and it can be viewed as a measure of the resolving power of an experiment needed to discriminate between two alternative hypothesis of a parameter.
When there are N parameters, then the Fisher information takes the form of an NxN positive semidefinite symmetric matrix, the Fisher Information Matrix, with typical element:
Under certain regularity conditions, the Fisher Information Matrix may also be written in the following form, which is often more convenient for computation:
With iid random variables, an N-dimensional "box" can be constructed with sides . Costa and Cover show that the (Shannon) differential entropy h(X) is related to the volume of the typical set (having the sample entropy close to the true entropy), while the Fisher information is related to the surface of this typical set.
Read more about this topic: Beta Distribution, Parameter Estimation
Famous quotes containing the words fisher, information and/or matrix:
“... word-sniffing ... is an addiction, like glue—or snow—sniffing in a somewhat less destructive way, physically if not economically.... As an addict ... I am almost guiltily interested in converts to my own illness, and in a pinch I can recommend nearly any reasonable solace, whether or not it qualifies as a true descendant of Noah Webster.”
—M.F.K. Fisher (1908–1992)
“I am the very pattern of a modern Major-Gineral,
I’ve information vegetable, animal, and mineral;
I know the kings of England, and I quote the fights historical,
From Marathon to Waterloo, in order categorical;”
—Sir William Schwenck Gilbert (1836–1911)
“In all cultures, the family imprints its members with selfhood. Human experience of identity has two elements; a sense of belonging and a sense of being separate. The laboratory in which these ingredients are mixed and dispensed is the family, the matrix of identity.”
—Salvador Minuchin (20th century)