Example: Bivariate Probit
are two binary dependent variables. In the Ordinary Probit model, one latent variable is used, in the bivariate probit model there are two: and . These latent variables are defined as: 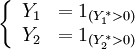
with
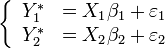
And:

Fitting the bivariate probit model involves estimating the values of . To do so, the Likelihood of the model has to be maximized. This Likelihood is defined as:
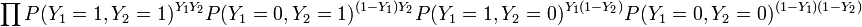 Substituting the latent variables and in the Probability functions and taking Log's gives:
Substituting the latent variables and in the Probability functions and taking Log's gives: 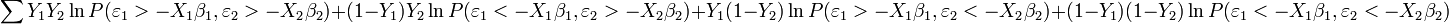
After some rewriting, the log-likelihood function becomes: 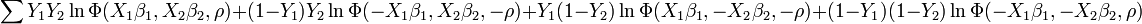 Note that is the cumulative distribution function of the bivariate normal distribution. and in the log-likelihood function are observed variables being equal to one or zero.
Note that is the cumulative distribution function of the bivariate normal distribution. and in the log-likelihood function are observed variables being equal to one or zero.
To maximize the log-likelihood function it is recommended to define the gradient.
Read more about this topic: Multinomial Probit